Deep Dive into the world of LLMs
LLM Model a game changer to the world of AI
This blog post focuses on the LLM models. We will learn what LLM exactly are? What is happening begind the large LLM. We will also learn how a chatGpt model is build in detailed.
The whole created for this blog post is goes to Andrej Karpathy he was a founding member at OpenAI (2015) and then Sr. Director of AI at Tesla (2017-2022), and is now a founder at Eureka Labs, which is building an AI-native school. His goal in this blog is to raise knowledge and understanding of the state of the art in AI, and empower people to effectively use the latest and greatest in their work.
You can find more about him at Karpathy Blogs and X
You can Watch full Video here.
Above Video is for the general audience deep dive into the Large Language Model (LLM) AI technology that powers ChatGPT and related products. It is covers the full training stack of how the models are developed, along with mental models of how to think about their “psychology”, and how to get the best use them in practical applications. I have one “Intro to LLMs” video already from ~year ago, but that is just a re-recording of a random talk, so I wanted to loop around and do a lot more comprehensive version.
Stages of Model Training
1. Pre-Training
Step 1: Download and Preprocess the internet
- Gather a massive dataset of text from diverse sources (e.g., books, websites).
- The performance of a large language model (LLM) depends heavily on the quality and size of its pretraining dataset. However, the pretraining datasets for state-of-the-art open LLMs like Llama3 and Mixtral are not publicly available and very little is known about how they were created.
- Hugging Face released a 🍷 FineWeb, a new, large-scale (15-trillion tokens, 44TB disk space) dataset for LLM pretraining. FineWeb is derived from 96 CommonCrawl snapshots and produces better-performing LLMs than other open pretraining datasets.
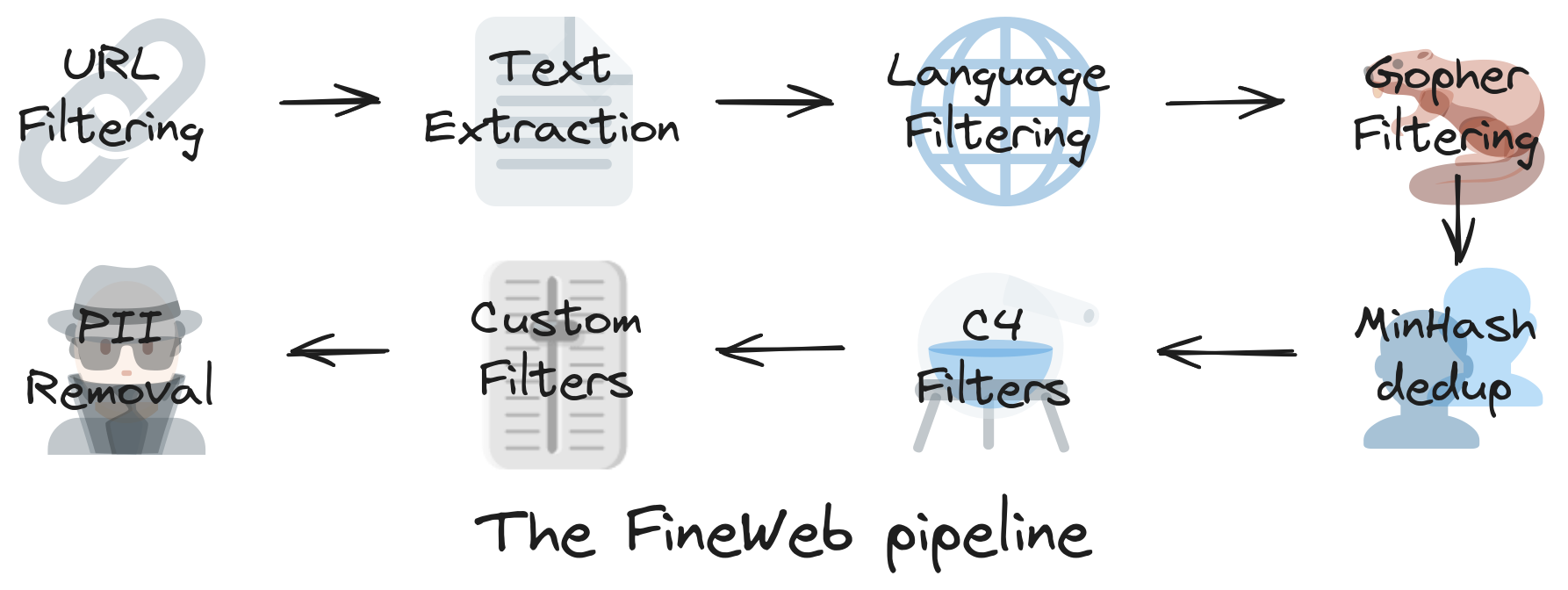
The key steps in this pipeline are:
- URL Filtering: Remove documents originating from malicious and NSFW(Not safe for work) websites using both block-lists and subword detection.
- Text Extraction: Utilize the Trafilatura tool to extract the main text content from raw HTML in CommonCrawl’s WARC files.
- Language Filtering: Apply the FastText language classifier to retain only English documents, discarding those with an English language score below 0.65.
- Quality Filtering: Implement multiple filters to ensure content quality:
- Gopher Repetition/Quality Filter: Detect and remove repetitive or low-quality text.
- C4 Quality Filters: Apply filters similar to those used in the C4 dataset, excluding the ‘terminal_punct’ rule.
- Custom Filters: Employ heuristics to eliminate list-like documents, texts with repeated lines, and those with improper formatting.
- Deduplication: Perform MinHash deduplication on each CommonCrawl dump individually, using 5-grams and 14x8 hash functions to identify and remove duplicate content.
- PII Anonymization: Anonymize personally identifiable information by replacing email addresses and public IP addresses with placeholder text.
Step 2: Tokenization
- Convert text into smaller units (tokens) for model processing.
- Tokenization is the process of breaking text into smaller pieces called tokens, like words or subwords.
- We use it in NLP to help computers understand and process text by turning sentences into manageable parts that models can analyze.
We need tokenization because computers can’t understand raw text. So, ‘By breaking text into smaller parts (tokens), it:
- Simplifies processing: Makes it easier for models to analyze and learn patterns.
- Handles complex words: Helps in understanding different word forms and variations.
- Improves efficiency: Speeds up computations by working with smaller units.
Converts text <—> sequences of symbols (/tokens)
- Start with stream of bytes (256 tokens)
- Run the Byte Pair Encoding algorithm (iteratively merge the most common token pair to mint new token)
1
2
3
4
Example: ~5000 text characters
~= 40,000 bits (with vocabulary size of 2 tokens: bits 0/1)
~= 5000 bytes (with vocabulary size of 256 tokens: bytes)
~= 1300 GPT-4 tokens (vocabulary size 100,277)
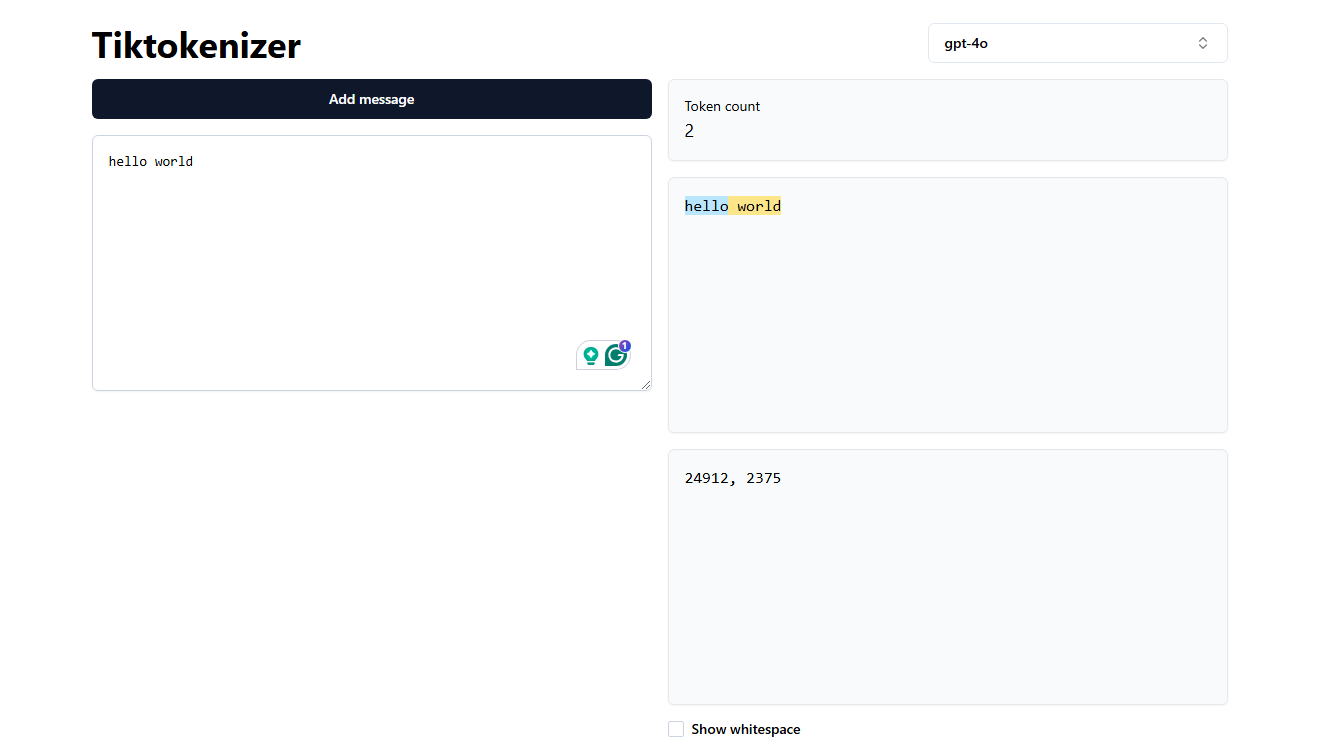
Tiktokenizer:- use the webisite to explore the tokens
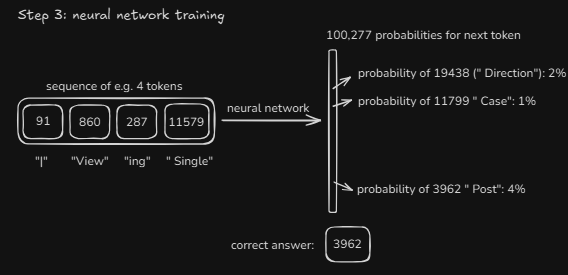
Step 3: Neural Network Training
Train a transformer neural network on large-scale text data to learn language patterns and context.
In a neural network, the Input/Output (I/O) works as follows:
Input (I):
- Purpose: Feeds data into the neural network.
- Examples: Text, images, audio, or numerical data.
- Format: Usually represented as numerical vectors (e.g., pixel values for images or token embeddings for text).
Output (O):
- Purpose: Provides the model’s prediction or result.
- Examples: Class labels (e.g., cat/dog), probabilities, or generated text.
- Format: Depends on the task:
- Classification: Probability distribution over classes.
- Regression: Continuous numerical values.
- Generation: Sequences like text or audio.
The neural network processes the input through multiple layers and generates an output that represents its prediction or decision.
Step 4: Inference
To generate data, just to predict one token at a time, we Use a next-word prediction task to enable the model to generate coherent text.